Heap 시리즈
[Heap] Background : Memory Allocator
[Heap] Background : Bin (Fastbin, Unsorted bin, Small bin, Large bin) (tistory.com)
[Heap] Memory Corruption : Use After Free(UAF) (1)
Memory Allocator
- Memory Allocator는 컴퓨터계의 부동산 중개업자!
- 부동산 중개업자는 매물을 파는 사람과 사는 사람들과 모두 교류하고 최대한 공실이 없게 집을 사고팔도록 함. (구매자가 집을 원한다고 갑자기 집을 새로 짓지 않는 것처럼!)
- 또한 구매자의 요구 조건에 맞는 매물을 찾아서 줌
- Memory Allocator도 메모리 반환과 할당을 책임짐. 또한 어떤 변수가 메모리 할당을 요구할 경우, 그 변수에 알맞은(ex 자료형, 사이즈) 메모리를 할당해줌
- 그리고 이미 반환된 메모리의 정보를 저장해서, 이와 비슷한 변수의 메모리 할당요청이 들어오면 그 저장한 메모리를 반환해줌(공실 없게!) - ptmalloc의 특징
- dlmalloc, ptmalloc2, jemalloc, tcmalloc, libumem, 등이 있음
요약하면 Memory Allocator는 메모리를 할당,반환하고, 공실 없게 반환된 메모리의 정보를 저장하고, 요구 조건에 알맞은 메모리를 찾아서 줌
Memory Allocator도 어떤 방식으로 메모리를 효율적으로 배분하는지의 그 알고리즘에 따라서 여러가지로 구분되어있음
우리는 오늘 ptmalloc이라는 리눅스의 Memory Allocator에 대하여 볼 것이다!
ptmalloc2
ptmalloc은 dlmalloc 기반 코드에서 멀티스레딩 기법을 확장한 메모리 할당자이다.
1. 메모리 낭비 방지
2. 빠른 메모리 재사용
3. 메모리 단편화(fragmentation) 방지
4. 멀티스레딩 기법 사용메모리 낭비 방지 및 빠른 메모리 재사용
- ptmalloc은 어떤 메모리가 해제되면, 그 메모리의 특징을 기억하고 있다가(tcache/bin에 크기별로 저장) 비슷한 메모리의 할당 요청이 오면 해제된 메모리에서 쓸만한 메모리를 찾고 걔를 바로 반환해줌 (마치 집을 다시 짓는게 아니라 빈 집을 주는 것처럼) 또한 예를 들어 4byte짜리 메모리 할당해달라고 하면 tcache에서 4byte짜리 있는지 찾아봄

메모리 단편화(Fragmentation) 방지
단편화란?
- 내부 단편화 : 메모리 블록의 크기보다 저장되는 데이터가 작을 때 발생하는 메모리 낭비
- 외부 단편화 : 메모리들을 저장하고 애매하게 남는 공간이 있는것. 예를들어 메모리 블록의 크기보다 데이터 크기가 커서 메모리가 들어가지 못하는 경우가 있을 수 있음
ptmalloc의 방지 기법 - 정렬(Allignment), 병합(Coalescence), 분할(Split)
- 정렬(Allignment) - 메모리 공간을 16byte단위로 할당함(64bit환경) ex) 17byte변수의 메모리 할당인 경우 32byte 할당해주고, 13byte 메모리 할당인 경우 16byte 할당해줌
- 병합(Coalscence) & 분할(Split) - 해제된 메모리들을 좀좀따리 모아서 병합하고 걔네를 또 나누어서 메모리 할당
단편화에 대해서는 따로 포스팅을 올릴 예정이다! 여기서는 간단히만 짚고 넘어가도록 하겠다.
멀티스레딩 기법 사용
ptmalloc2에서는, 동일한 시간에 2개의 스레드가 malloc을 호출할 경우, 메모리는 각각의 스레드가 분배된 힙 영역을 일정하게 유지하고, 힙을 유지하기 위한 freelist data structures 또한 분배되어 있기 때문에 즉시 할당된다. 이렇게 각각의 스레드의 유지를 위해 분배된 힙과 freelist data structures의 행동을 per thread arena라고 부른다. (여기)
- 복수의 스레드가 동시에 malloc을 호출하면 각 스레드는 별도의 힙 세그먼트가 생성되고, 해당 힙을 유지 보수하는 데이터 구조도 분리되어 메모리에 할당됨
- 따라서 서로 다른 스레드가 서로 간섭하지 않고 서로 다른 메모리 영역에 접근 할 수 있음
- 스레드에 대하여 더 알고 싶다면? -> go to [🖥️ Computer Science/OS] - [OS] 스레드(Thread)
멀티스레드 환경에서 힙이 어떻게 관리되는지 실습을 통해서 확인해보자.
/* Per thread arena example. */
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
void* threadFunc(void* arg) {
printf("Before malloc in thread 1\n");
getchar();
char* addr = (char*) malloc(1000);
printf("After malloc and before free in thread 1\n");
getchar();
free(addr);
printf("After free in thread 1\n");
getchar();
}
int main() {
pthread_t t1;
void* s;
int ret;
char* addr;
printf("Welcome to per thread arena example::%d\n",getpid());
printf("Before malloc in main thread\n");
getchar();
addr = (char*) malloc(1000);
printf("After malloc and before free in main thread\n");
getchar();
free(addr);
printf("After free in main thread\n");
getchar();
ret = pthread_create(&t1, NULL, threadFunc, NULL);
if(ret)
{
printf("Thread creation error\n");
return -1;
}
ret = pthread_join(t1, &s);
if(ret)
{
printf("Thread join error\n");
return -1;
}
return 0;
}
[ Main Thread에서 malloc 호출 전 ]


malloc을 하지 않았는데도 heap이 있는 것을 볼 수 있다. 왜냐하면 main arena(main thread로부터 만들어진 힙 비스무리한 영역이라고 보면 된다. arena에 대해서는 다른 포스트에서 다룬다.)에서는 malloc과 같은 메모리 할당 요청 없이도 initial heap이 만들어지기 때문이다.
[ Main Thread에서 malloc 호출 이후 ]


할당 요청은 main arena를 사용하여 비어있는 공간이 없어질 때 까지 유지하면서 사용한다. 1000을 할당했는데 새로 메모리를 할당한게 아니라 아까 할당된 arena(힙) 안에서 메모리를 할당한 것을 볼 수 있다. arena가 꽉 찼을 경우 프로그램의 break 위치를 증가시킴으로써 더욱 확장 수 있다 (top 청크의 크기를 증가시켜 여분의 공간을 포함할 수 있도록 조정한 후! top 청크는 힙 맨 아래(주소는 맨 위에)있는 청크이다!). 이와 비슷하게 top 청크에 비어있는 공간이 많은 경우, arena는 또한 줄어들 수도 있다.
[ Main Thread에서 free 호출 이후 ]
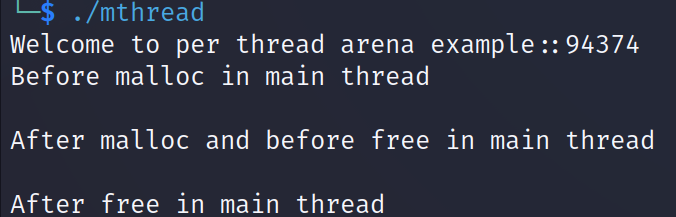
free를 했음에도 heap 영역이 딱히 줄지 않은 것을 볼 수 있다. 왜냐하면 bin이라는 해제된 메모리를 관리하는 영역에 들어갔기 때문이다. 이후 메모리를 할당하면 이 bin에서 메모리를 다시 꺼내서 활용한다 (bin은 다른 포스트에 있음)
[ thread1에서의 malloc 호출 이전 ]
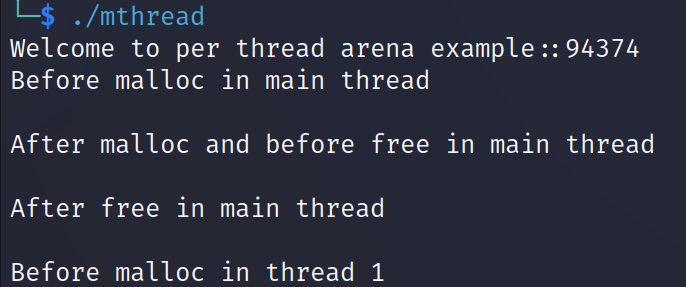

스레드 포스트에서도 다뤘듯이 멀티스레드 프로세스에서 각각의 스레드들은 스택을 따로 생성해서 거기서 논다. 하지만 다른 메모리 영역들은 공유한다.
[ thread1에서의 malloc 호출 ]
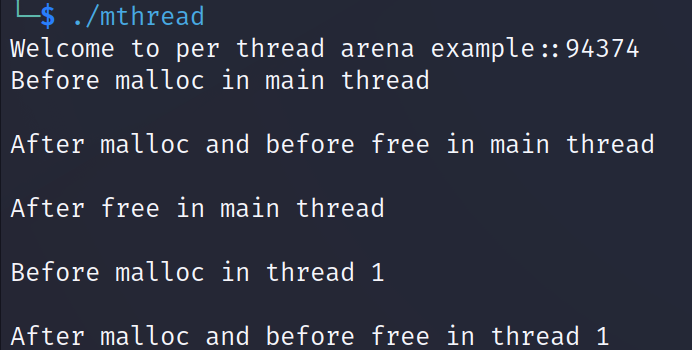

7f9e3400000~7f9e3800000 의 부분이 추가적으로 생성되었다. 이 부분은 mmap으로 생성된 thread1의 새로운 힙 부분이다.
기타 Allocator
논문 리뷰하다가 dlmalloc이랑 jemalloc도 나와서 이것도 간략하게 특징을 정리했다 오랜만에 포너블에서 했던거 나와서 넘 즐거웠당ㅎㅎ
저번에 jemalloc아시냐고 해서 모른다고 했었는데 보니까 그냥 ptmalloc이랑 거의 비슷한 것 같다 차피 다 거기서 거기여서 !!
(아는 내용 제외하고 새로 알게된 내용만 정리했다!)
dlmalloc
- chunk는 segment라는 pool에서 allocate된다고 한다 (이게 이 allocator에서만 적용되는 것인지는 모르겠지만 찾아봐야겠다)
- 그리고 커널에서 sbrk, mmap 시스템콜에 의해 할당된다. 아마 malloc같은 애 안에서 최종적으로 저 syscall을 호출하는 듯? 궁금해서 strace로 돌려봤다.(참고로 돌린 코드는 ptmalloc2 사용) 소스코드는 그냥 멈춰서 분석하기 위해 read 한 번 해주고 malloc(0x30), malloc(0x1000000) 해준 코드다
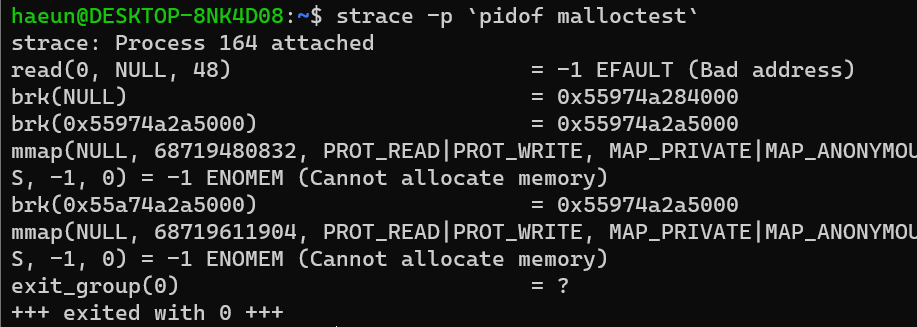
일단 malloc(0x30)짜리는 brk로 하고 있고, malloc(0x100000) 얘는 mmap으로 할당해주고 있는 걸 확인할 수 있었다!
brk나 sbrk나 거의 똑같다! brk와 sbrk는 그냥 데이터 세그먼트 자체를 늘려주는 system call이라고 생각하면 된다!
| syscall | 역할 | 방식 | 반환 값 |
| brk | 데이터 세그멘트 크기 변경 | brk의 인자인 addr에서 지정한 값으로 설정 | 성공(0), 실패(1), 에러(ENOMEM) |
| sbrk | 데이터 세그멘트 크기 변경 | 데이터 세그멘트를 increment bytes만큼 증가 | 성공(이전 program break값), 실패(void포인터 형으로 -1), 에러(ENOMEM) |
| mmap | 새 가상메모리 영역 요청 | [[C/C++] mmap 함수 | 성공(매핑된 메모리 주소 반환), 실패(MAP_FAILED) |
- 엄청 큰 chunk들은 page-alligned된다고 한다! 그리고 mmap이랑 munmap으로 할당되어서 딱히 large chunk를 reuse하지는 않는듯? (즉 free list를 사용하지 않는듯) 참고로 large bin에 들어가는 애들이보다 훨 큰 chunk를 말하는 것 같다
- 아래는 내가 예전에 정리한 블로그 내용인데 이 내용이랑 비슷한 것 같다 (https://hannahsecurity.tistory.com/entry/Heap-Chunk#article-2-1-1--prev_size)

- 병합의 이유는 external framentation 막기 위해서라구 한다!!
jemalloc
이 allocator는 Facebook에서 사용한다고 한다.
논문에서 citation 타고 들어갔는데 여기서 굉장히 자세히 설명해주시고 있다. 그래서 이걸 보고 내용을 정리했다
https://engineering.fb.com/2011/01/03/core-infra/scalable-memory-allocation-using-jemalloc/
Scalable memory allocation using jemalloc
Visit the post for more.
engineering.fb.com
- 작은 객체를 size class로 나누고, 재사용시 '낮은 주소'의 재사용 지향
- Size Class를 신중하게 고른다!
- size class가 멀리 떨어져 있으면 internal fragmentation 높아짐
- size class의 수가 늘어나면 external framentation이 높아짐
- 멀티스레딩 환경을 지원하기 위해 arena 사용 (이 부분은 ptmalloc이랑 거의 비슷한 것 같다)
- 프로그램 동시성 지원, arena 개수는 CPU 코어 개수에 비례
- 스레드 별로 arena를 할당받고, 각 arena는 서로 독립되어있음.
- 각 arena는 각 스레드의 청크들을 관리
- cache도 있고 (얘가 tcache인듯) 이 캐시에 접근하면 따로 arena를 안 접근해도 됨

- chunk가 small, large, huge로 구분된다!! 여기서 huge 부분은 내가 알고 있던 allocator의 성질과 조금 달랐다
- dlmalloc과는 다르게 huge chunk는 메모리를 release하지 않았고 reserve해 놓는다!! 그래서 따로 huge chunk에 대한 자료구조가 존재한다고 한다.
References
https://engineering.fb.com/2011/01/03/core-infra/scalable-memory-allocation-using-jemalloc/
https://ui.adsabs.harvard.edu/abs/2024IEEEA..12.5462B/abstract
'Linux Exploitation > Heap' 카테고리의 다른 글
| [Heap] Exploitation : Double Free Bug (0) | 2023.06.15 |
|---|---|
| [Heap] Exploitation : Unsorted Bin Memory Leak (0) | 2023.06.11 |
| [Heap] Background : Bin (Fastbin, Unsorted bin, Small bin, Large bin) (1) | 2023.06.09 |
| [Heap] Background : Chunk (3) | 2023.06.07 |
| [Heap] Memory Corruption : Use After Free(UAF) (0) | 2023.05.30 |
